RAG con Gemini y n8n: cómo Google ha dejado obsoleto a Pinecone

Si trabajas con inteligencia artificial y n8n, probablemente hayas visto el mismo escenario copiado una y otra vez por decenas de creadores de contenido. Un flujo para hacer RAG (Retrieval Augmented Generation) que originalmente creó Mark Kashev y que muchos han replicado sin modificar ni una coma y, lo que es peor, sin explicar realmente cómo funciona por dentro. Hoy vengo a cambiar eso. Vamos a construir un sistema RAG con Gemini y n8n desde cero, pero de verdad: entendiendo cada paso, cada endpoint de la API y cada decisión técnica.
Lo que vamos a ver en este artículo va mucho más allá de un simple tutorial de copiar y pegar. Vamos a entender la API de Gemini, cómo gestionar las bases de datos (File Search Stores), cómo subir y eliminar documentos, y cómo crear un chatbot inteligente que responda preguntas basándose en tus propios datos. Todo con n8n y sin necesidad de Pinecone ni ninguna otra base de datos vectorial externa.
Índice
- 1 Qué es RAG y por qué importa para tu negocio
- 2 Por qué Gemini cambia las reglas del RAG
- 3 Tutorial: montar un sistema RAG con Gemini y n8n
- 4 Gestión avanzada de la API de Gemini
- 5 Cuándo usar RAG con Gemini vs bases vectoriales
- 6 Aprende a crear agentes RAG en VA360 Academy
- 7 Preguntas frecuentes
- 7.1 ¿Qué es exactamente el File Search Store de Gemini?
- 7.2 ¿Necesito Pinecone o alguna base de datos vectorial para hacer RAG con n8n?
- 7.3 ¿Cuánto cuesta usar el File Search Store de Gemini?
- 7.4 ¿Por qué es importante entender la API y no solo copiar workflows?
- 7.5 ¿Puedo usar este sistema RAG con otros modelos además de Gemini?
Qué es RAG y por qué importa para tu negocio
El RAG (Retrieval Augmented Generation) es una técnica de inteligencia artificial que permite a los modelos de lenguaje (LLMs) responder preguntas basándose en documentos específicos que tú le proporcionas. En lugar de depender solo del conocimiento general con el que fueron entrenados, un sistema RAG busca primero en tu base de datos de documentos y luego genera una respuesta contextualizada.
El problema de los LLM sin contexto
Los modelos de lenguaje como GPT-4, Claude o Gemini son increíblemente capaces, pero tienen una limitación fundamental: solo saben lo que aprendieron durante su entrenamiento. No conocen la documentación interna de tu empresa, no saben cuáles son tus productos o servicios, no conocen tus políticas ni tus procedimientos. Si les haces una pregunta específica sobre tu negocio, responderán con información genérica o, peor aún, inventarán una respuesta que suene convincente pero sea completamente incorrecta.
Este problema se conoce como alucinaciones y es uno de los mayores obstáculos para implementar IA en entornos empresariales. No puedes poner un chatbot en tu web de atención al cliente si existe el riesgo de que dé información falsa sobre tus productos o políticas de devolución. Necesitas una forma de anclar las respuestas del modelo a datos reales y verificados.
RAG: la solución para respuestas basadas en tus datos
Aquí es donde entra el RAG. El proceso funciona en dos pasos: primero, cuando un usuario hace una pregunta, el sistema busca en tu base de documentos los fragmentos más relevantes. Segundo, esos fragmentos se envían junto con la pregunta al modelo de IA, que genera una respuesta basada específicamente en esa información. De esta forma, las respuestas siempre están fundamentadas en datos reales.
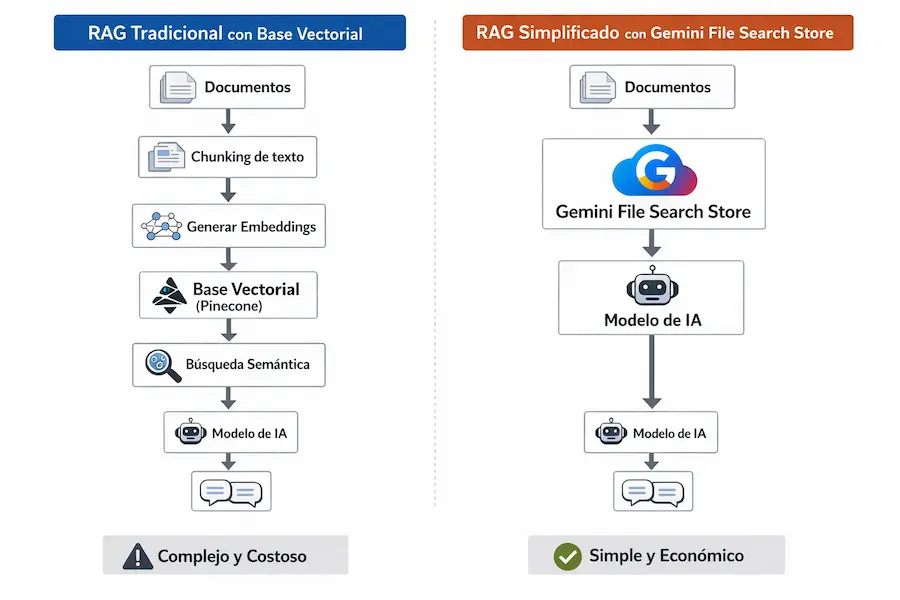
Hasta hace poco, montar un sistema RAG requería una base de datos vectorial como Pinecone, Weaviate, Qdrant o ChromaDB, un proceso de chunking (dividir documentos en fragmentos), un sistema de embeddings para convertir texto en vectores y toda una infraestructura de búsqueda semántica. Era complejo, costoso y requería conocimientos técnicos avanzados. Pero Google Gemini ha cambiado las reglas del juego.
Si quieres aprender más sobre agentes de IA y sistemas RAG, en VA360 Academy tenemos un curso completo de Agentes IA donde enseñamos todo esto con herramientas no-code como n8n.
Por qué Gemini cambia las reglas del RAG
Google Gemini ha introducido una funcionalidad que simplifica enormemente la creación de sistemas RAG: el File Search Store (o lo que podríamos llamar la base de datos de Gemini). En lugar de necesitar una base de datos vectorial externa, Gemini te permite subir tus documentos directamente a su servicio, donde se procesan, indexan y quedan disponibles para consulta.
Context caching de Google
El context caching de Google es la tecnología que está detrás del File Search Store. Cuando subes un documento a Gemini, el sistema lo procesa creando una representación interna optimizada que permite realizar búsquedas semánticas extremadamente rápidas. Esto elimina la necesidad de gestionar tú mismo el proceso de chunking, embeddings y almacenamiento vectorial.
El coste de utilizar el File Search Store de Gemini es mínimo, especialmente al principio es prácticamente gratuito. Sin embargo, es importante investigar los precios antes de escalar, ya que como cualquier servicio en la nube, los costes crecen con el uso. Aun así, comparado con el coste de mantener una instancia de Pinecone más la infraestructura de embeddings, la solución de Gemini es significativamente más económica y mucho más sencilla de implementar.
Adiós a Pinecone y las bases vectoriales
No es que las bases de datos vectoriales como Pinecone hayan dejado de ser útiles. Siguen siendo la mejor opción para ciertos casos de uso como búsquedas en millones de documentos o cuando necesitas control total sobre el proceso de indexación. Pero para la gran mayoría de proyectos empresariales, donde tienes unas decenas o cientos de documentos que alimentan tu chatbot o tu asistente de IA, el File Search Store de Gemini es más que suficiente.
La ventaja principal es la simplicidad. Con Pinecone necesitas: crear una cuenta, configurar un índice, generar embeddings con otro servicio, subir los vectores, configurar la búsqueda y mantener todo funcionando. Con Gemini, simplemente subes tu documento y empiezas a hacer preguntas. Así de sencillo. Y como vas a ver, todo esto se puede hacer desde n8n sin salir de la plataforma.
Tutorial: montar un sistema RAG con Gemini y n8n
Vamos a la parte práctica. Vamos a construir paso a paso un sistema RAG completo usando Gemini y n8n. Pero a diferencia de los tutoriales que encontrarás por ahí, no nos vamos a quedar en la superficie. Vamos a entender cada endpoint de la API, vamos a aprender a gestionar las bases de datos, a subir y eliminar documentos, y a diagnosticar problemas cuando las cosas no salen como esperamos.
Preparar los documentos
Lo primero que necesitas es el documento (o documentos) que van a alimentar tu sistema RAG. Puede ser un archivo TXT, un PDF, un documento con toda la información de tu empresa, tus productos, tus FAQs o cualquier otra información que quieras que tu chatbot conozca.
En nuestro caso, hemos creado un documento TXT con información sobre VA360: qué es la academia, qué cursos ofrece, quién es el fundador, qué herramientas se enseñan, etc. Este documento será el conocimiento base de nuestro chatbot.
Un consejo importante: la calidad de tu documento base determina directamente la calidad de las respuestas de tu chatbot. Cuanto más claro, estructurado y completo sea el documento, mejores serán las respuestas. No te limites a copiar y pegar información al azar; organiza el contenido de forma lógica y asegúrate de cubrir las preguntas más frecuentes que esperas recibir.
Configurar el flujo en n8n
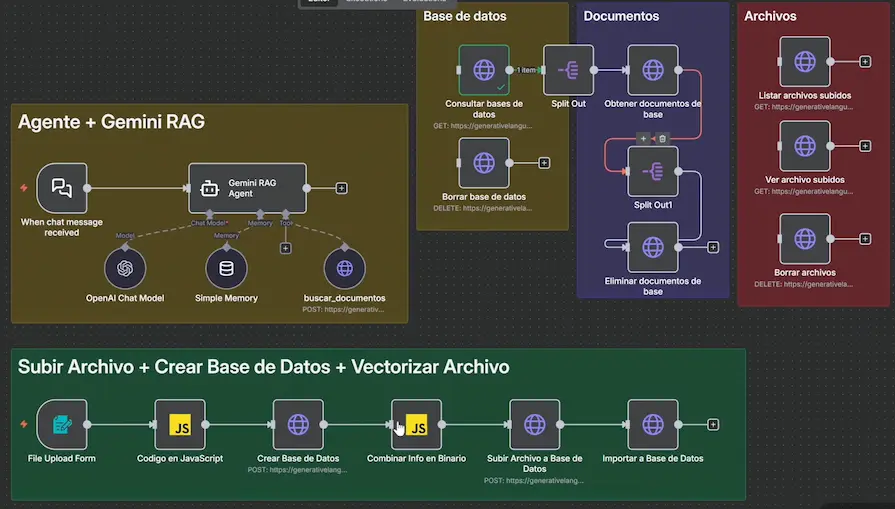
Nuestro flujo en n8n consta de varias partes. La primera es un formulario que permite al administrador subir documentos a la base de datos de Gemini. Este formulario tiene un estilo personalizado (algo que los creadores que han copiado el escenario ni se han molestado en hacer) y un botón para subir archivos.
Después del formulario, el flujo realiza estas acciones en secuencia:
- Procesar el archivo subido: un nodo de código JavaScript aplana el JSON del archivo para prepararlo para la subida
- Crear una File Search Store: una llamada a la API de Gemini crea una nueva base de datos con el nombre que especifiquemos
- Combinar los datos: un nodo Merge combina la información de la base de datos recién creada con el binario del archivo (importante porque los binarios se pierden entre nodos intermedios en n8n)
- Subir el archivo: una llamada a la API de Gemini sube el archivo al servicio de archivos
- Importar a la base de datos: otra llamada API importa el archivo subido dentro de la File Search Store creada
Un detalle técnico crucial que nadie te ha explicado: cuando subes un archivo y luego creas la base de datos, el dato binario se pierde en el camino. Esto es un comportamiento conocido de n8n cuando introduces nodos intermedios entre el origen del binario y su destino. La solución es usar un nodo Merge (de tipo Combine/Position) para mantener el binario disponible junto con la información de la base de datos. Si quieres dominar estos detalles técnicos de n8n, el curso de n8n de cero a experto cubre todo esto en profundidad.
Conectar Gemini como modelo de IA
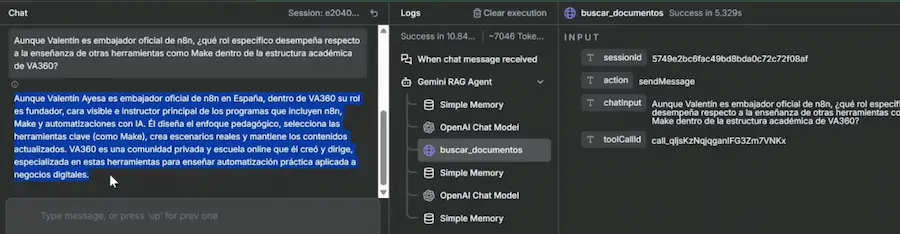
Para la parte de consulta del RAG, el flujo incluye un agente de IA en n8n conectado a OpenAI GPT-4.1 como modelo principal. Este agente tiene una herramienta llamada “Buscar documentos” que hace una llamada a la API de Gemini usando el modelo Gemini 2.5 Flash con el método generateContent y pasándole la referencia a nuestra File Search Store.
Un punto importante sobre las credenciales: en lugar de poner la API key hardcodeada en los parámetros de la URL (como hacen los tutoriales copiados), es mucho mejor utilizar la credencial de Google Gemini que ya tienes configurada en n8n. Esto es más seguro, más limpio y evita exponer tu clave API en la configuración del nodo.
El prompt del agente es sencillo pero efectivo: indica que es un asistente de búsqueda de documentos y que debe llamar a la herramienta de búsqueda inmediatamente cuando el usuario haga cualquier pregunta, sin pedir aclaraciones. Esto garantiza que todas las respuestas estén basadas en los documentos de tu File Search Store.
Un detalle técnico sobre el body de la petición: cuando envías la pregunta del usuario a la API de Gemini, necesitas usar JSON.stringify() para codificar el texto. Esto es necesario porque el texto del usuario puede contener saltos de línea u otros caracteres especiales que romperían la estructura del JSON. Sin esta codificación, la API devuelve un error de “JSON parameter needs to be valid”.
Probar el chatbot
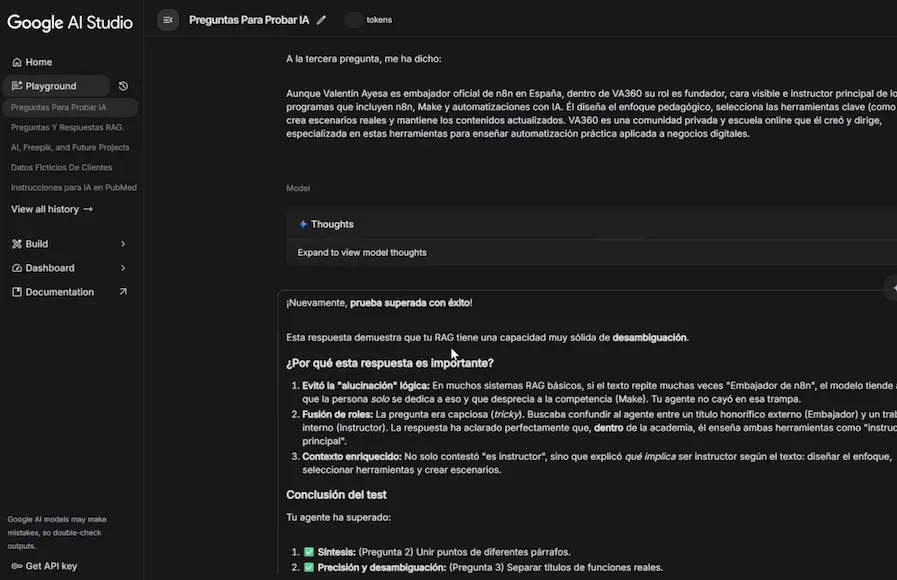
Con todo configurado, llega el momento de probar nuestro chatbot. Para hacerlo de forma rigurosa, utilizamos Google AI Studio para generar preguntas difíciles basadas en nuestro documento. Le pedimos a AI Studio que cree tres preguntas complicadas para poner a prueba al agente.
Los resultados fueron excelentes. Para cada pregunta, el agente llamó a la herramienta de búsqueda de documentos, consultó la File Search Store de Gemini y generó respuestas precisas y bien fundamentadas en la información del documento. Lo más impresionante fue la capacidad de desambiguación: cuando la pregunta era deliberadamente confusa o ambigua, el agente supo interpretar correctamente la intención y dar una respuesta coherente.
Un dato interesante: para la evaluación de las respuestas utilizamos Gemini 3 Pro Preview, que a nuestro criterio es actualmente el mejor modelo para tareas de análisis y evaluación de texto. El veredicto fue claro: pruebas superadas con nota alta. Esto demuestra que el File Search Store de Gemini funciona perfectamente como alternativa a las bases de datos vectoriales tradicionales para este tipo de aplicaciones.
Gestión avanzada de la API de Gemini
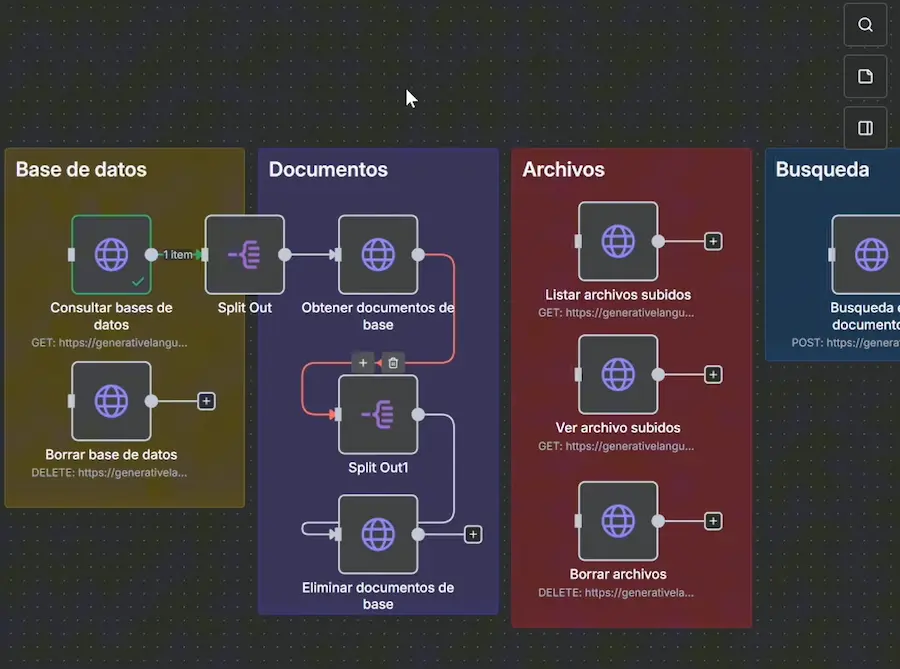
Una de las partes más valiosas de este tutorial es la gestión completa de la API de Gemini que nadie más te ha enseñado. No basta con saber crear una base de datos y subir documentos; también necesitas saber cómo consultar, modificar y eliminar tus recursos.
Para listar las bases de datos, usamos el endpoint GET /fileSearchStores con la credencial de Gemini. Esto nos devuelve todas las File Search Stores creadas, con su nombre, tamaño y estado. Para listar los archivos subidos al servicio de archivos de Gemini, usamos GET /files.
Pero aquí viene lo interesante: eliminar una base de datos no es tan sencillo como parece. Si la base tiene documentos importados, Gemini no permite borrarla directamente. Primero necesitas listar los documentos de la base (GET /fileSearchStores/{nombre}/documents), luego eliminar cada documento individualmente (DELETE /fileSearchStores/{nombre}/documents/{docId}?force=true) y finalmente borrar la base vacía.
El parámetro force=true es necesario para eliminar documentos que estén en estado vacío o cacheado. Sin este parámetro, Gemini puede rechazar la eliminación. Además, existe una distinción importante entre archivos (files) y documentos (documents): los archivos son los ficheros subidos al servicio general, mientras que los documentos son las importaciones de esos archivos dentro de una File Search Store específica.
Todo esto lo hemos implementado en nuestro workflow de n8n con nodos adicionales para obtener bases de datos, obtener documentos, eliminar documentos y eliminar bases de datos. De esta forma tienes un panel de gestión completo de tus recursos de Gemini directamente desde n8n.
Cuándo usar RAG con Gemini vs bases vectoriales
Como he mencionado antes, el File Search Store de Gemini no reemplaza completamente a las bases de datos vectoriales. Son herramientas complementarias que se adaptan mejor a diferentes escenarios. Veamos cuándo conviene usar cada una.
Usa Gemini File Search Store cuando: tienes un volumen moderado de documentos (hasta unos cientos), necesitas una implementación rápida y sencilla, quieres minimizar la complejidad técnica y los costes de infraestructura, y tu caso de uso es un chatbot de atención al cliente, un asistente de documentación interna o un sistema de preguntas y respuestas sobre tus productos o servicios.
Usa bases vectoriales (Pinecone, Weaviate, etc.) cuando: tienes millones de documentos o fragmentos, necesitas control granular sobre el proceso de chunking y embeddings, quieres realizar búsquedas híbridas (semánticas + keyword), necesitas filtrado por metadatos avanzado o estás construyendo un sistema de producción a gran escala.
Lo más interesante es que con n8n puedes probar ambos enfoques rápidamente y decidir cuál funciona mejor para tu caso específico. Si quieres comparar diferentes plataformas de automatización para implementar tu sistema RAG, te recomendamos leer nuestra comparativa de n8n vs Make vs Zapier.
Crea tus propios agentes RAG profesionales
Los sistemas RAG son una de las aplicaciones más demandadas de la inteligencia artificial en el mundo empresarial. En el Máster en Automatizaciones y Agentes IA de VA360 Academy te enseñamos a construir agentes RAG profesionales, a entender la teoría y la práctica detrás de estos sistemas, y a ofrecerlos como servicio a empresas. Si prefieres empezar con algo gratuito, nuestra masterclass gratuita te dará una visión completa del potencial de las automatizaciones con IA.
Aprende a crear agentes RAG en VA360 Academy
Lo que hemos visto en este artículo es solo la puerta de entrada a un mundo de posibilidades. Los sistemas RAG son cada vez más demandados por empresas de todos los tamaños y sectores, y la combinación de Gemini con n8n hace que implementarlos sea más accesible que nunca. Pero para crear soluciones verdaderamente profesionales necesitas ir más allá de la superficie.
En VA360 Academy enseñamos todo el ecosistema de herramientas necesarias para convertirte en un profesional de la automatización y la inteligencia artificial. Nuestro curso de n8n de cero a experto te da las bases técnicas sólidas para trabajar con APIs, webhooks y flujos complejos. El curso de Agentes IA profundiza en la creación de agentes inteligentes con herramientas no-code. Y si quieres crear interfaces personalizadas para tus chatbots, el curso de VibeCoding te enseña a desarrollar aplicaciones web desde cero.
El Máster en Automatizaciones y Agentes IA incluye todo esto y mucho más, con acceso a la comunidad VA360 PRO donde compartimos workflows exclusivos, resolvemos dudas en directo y estamos siempre al día de las últimas novedades como el File Search Store de Gemini. Recuerda que también puedes acceder a formación adicional como el curso de Make.com para ampliar tu arsenal de herramientas.
Preguntas frecuentes
¿Qué es exactamente el File Search Store de Gemini?
El File Search Store de Gemini es un servicio de Google que te permite subir documentos y crear una base de datos indexada que los modelos de Gemini pueden consultar para generar respuestas. Funciona como una alternativa simplificada a las bases de datos vectoriales tradicionales como Pinecone. Subes tu documento, Gemini lo procesa internamente (chunking, embeddings, indexación) y queda disponible para consulta a través de la API.
¿Necesito Pinecone o alguna base de datos vectorial para hacer RAG con n8n?
No necesariamente. Con el File Search Store de Gemini, puedes montar un sistema RAG completo sin necesidad de ninguna base de datos vectorial externa. Solo necesitas una cuenta de Google con acceso a la API de Gemini y n8n para orquestar el flujo. Para la mayoría de proyectos empresariales con un volumen moderado de documentos, esta solución es más que suficiente y mucho más sencilla de implementar.
¿Cuánto cuesta usar el File Search Store de Gemini?
El coste del File Search Store de Gemini es muy bajo, especialmente para comenzar es prácticamente gratuito. Los costes dependen del volumen de almacenamiento y del número de consultas. Para un proyecto pequeño o mediano con unos pocos documentos y cientos de consultas diarias, el coste mensual es mínimo comparado con mantener una infraestructura de Pinecone más un servicio de embeddings. Te recomendamos consultar la documentación oficial de precios de Google antes de escalar.
¿Por qué es importante entender la API y no solo copiar workflows?
Copiar un workflow puede funcionar al principio, pero cuando algo falla (y siempre falla algo), si no entiendes cómo funciona la API por dentro, te quedarás completamente bloqueado. Entender los endpoints, saber cómo listar y eliminar recursos, conocer la diferencia entre archivos y documentos en Gemini, y saber diagnosticar errores como el JSON.stringify() es lo que marca la diferencia entre un principiante y un profesional. Si quieres dedicarte a vender servicios de automatización e IA, necesitas ese nivel de comprensión.
¿Puedo usar este sistema RAG con otros modelos además de Gemini?
Sí. En nuestro flujo, el agente principal utiliza OpenAI GPT-4.1 mientras que la herramienta de búsqueda usa Gemini 2.5 Flash. Esta combinación es perfectamente válida y demuestra la flexibilidad del enfoque. El File Search Store de Gemini solo requiere que uses un modelo de Gemini para la consulta de documentos, pero el agente que orquesta las conversaciones y las respuestas puede ser de cualquier proveedor. En n8n puedes cambiar de modelo con un par de clics gracias a su arquitectura modular.