Imagina que puedes crear un chatbot que no solo responda preguntas genéricas, sino que conozca toda la documentación de tu empresa, tus productos, tus procesos internos y hasta las respuestas que tu equipo de soporte ha dado durante años. Eso es exactamente lo que permite RAG (Retrieval Augmented Generation), y lo mejor es que puedes implementarlo sin ser programador gracias a n8n.
Si alguna vez has probado ChatGPT o Claude y has pensado “esto está muy bien, pero no sabe nada de mi negocio”, entonces RAG es la solución que estabas buscando. En esta guía te voy a explicar paso a paso cómo construir un chatbot inteligente con RAG y n8n, desde la preparación de tus documentos hasta la conexión con WhatsApp, tu web o el canal que prefieras.
Y no, no necesitas saber programar. Con n8n y un poco de paciencia, cualquier persona puede montar un sistema RAG funcional en unas pocas horas. Vamos a ello.
Qué es RAG y por qué cambia las reglas del juego
RAG es una de las técnicas más potentes del mundo de la inteligencia artificial aplicada en 2026. Antes de entrar en la parte técnica, vamos a entender por qué es tan importante y qué problema resuelve.
El problema de los chatbots genéricos
Los modelos de lenguaje como GPT-4o, Claude 4 o Gemini 2.0 son increíblemente potentes para generar texto, responder preguntas y mantener conversaciones. Sin embargo, tienen un problema fundamental: no conocen tu negocio. No saben qué productos vendes, cuáles son tus políticas de devolución, qué dice tu documentación técnica ni cómo funciona tu proceso de onboarding.
Cuando le preguntas a un chatbot genérico sobre tu empresa, puede hacer dos cosas: inventarse la respuesta (lo que llamamos “alucinación”) o simplemente decir que no tiene esa información. Ninguna de las dos opciones es útil para tus clientes o tu equipo.
Y aquí es donde entra RAG: una técnica que permite a los LLMs acceder a tus propios datos antes de generar una respuesta, eliminando las alucinaciones y ofreciendo respuestas precisas y contextualizadas.
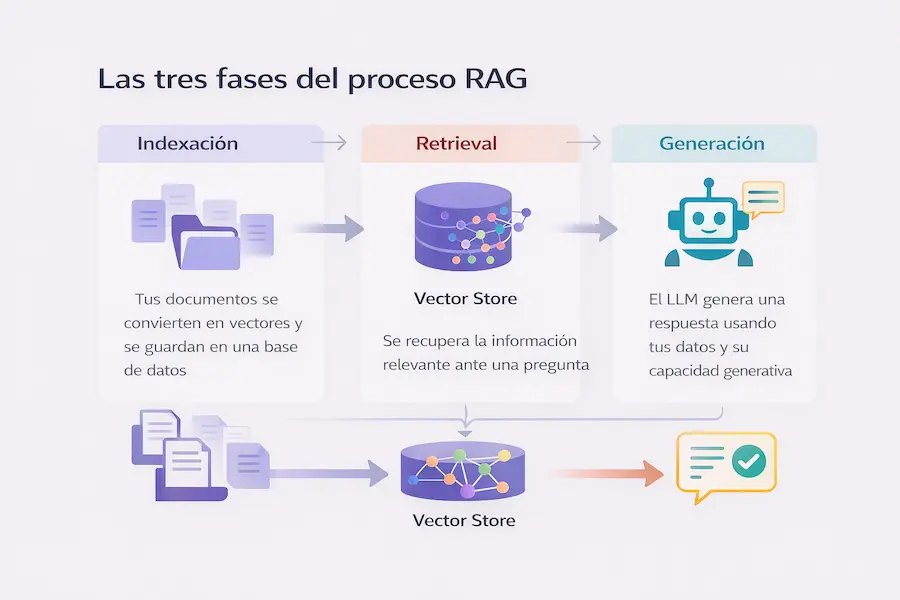
RAG funciona en tres fases principales. Primero, tus documentos se dividen en fragmentos pequeños y se convierten en vectores numéricos (embeddings) que se almacenan en una base de datos vectorial. Segundo, cuando un usuario hace una pregunta, esa pregunta también se convierte en un vector y se buscan los fragmentos más relevantes en tu base de datos. Tercero, esos fragmentos se envían junto con la pregunta al modelo de IA, que genera una respuesta basada en tu información real.
En resumen: Retrieval (buscar la información relevante) + Augmented (enriquecer el prompt con esa información) + Generation (generar la respuesta final). Es un proceso elegante que combina lo mejor de la búsqueda semántica con el poder generativo de los LLMs.
Las tres fases del proceso RAG: indexación, retrieval y generation
Por qué n8n es ideal para implementar RAG
n8n se ha convertido en la herramienta preferida para implementar sistemas RAG por varias razones. Primero, su interfaz visual permite construir flujos complejos sin escribir código. Segundo, tiene nodos nativos para conectar con OpenAI, Anthropic (Claude), Pinecone, Qdrant, Supabase y muchas más herramientas de IA. Tercero, al ser open-source, puedes autoalojarlo y mantener el control total de tus datos.
Además, n8n incluye desde 2025 un sistema de AI Agent que facilita enormemente la creación de chatbots con RAG. No necesitas ser un experto en machine learning; con los nodos adecuados y la configuración correcta, puedes tener tu chatbot RAG funcionando en horas.
Qué necesitas para crear un chatbot RAG con n8n
Antes de empezar a construir, asegúrate de tener preparados estos cuatro elementos esenciales. No te preocupes, te explico cada uno en detalle.
Una instancia de n8n
Necesitas tener n8n funcionando, ya sea en n8n Cloud (la opción más sencilla) o autoalojado en un servidor propio con Docker. Si estás empezando, te recomiendo n8n Cloud porque te ahorras toda la configuración del servidor. Si quieres aprender a instalarlo desde cero, en nuestro curso de n8n 2026 cubrimos ambas opciones con detalle.
Documentos o base de conocimiento
Esta es la materia prima de tu chatbot RAG. Pueden ser PDFs, páginas web, documentos de Google Drive, archivos de Notion, manuales técnicos o cualquier texto que contenga la información que quieres que tu chatbot conozca. Cuanto más organizada y completa sea tu base de conocimiento, mejores serán las respuestas.
Un modelo de IA (OpenAI, Claude o Gemini)
Necesitas un modelo de lenguaje para dos cosas: generar los embeddings (representaciones vectoriales de tus documentos) y generar las respuestas finales. Las opciones más populares en 2026 son OpenAI (GPT-4o), Anthropic (Claude 4) y Google (Gemini 2.0). Cada uno tiene sus ventajas en términos de precio, precisión y velocidad.
Un vector store (Pinecone, Qdrant o Supabase)
El vector store es la base de datos especializada donde se almacenan los embeddings de tus documentos. Las opciones más utilizadas con n8n son Pinecone (cloud, muy fácil de configurar), Qdrant (open-source, autoalojable) y Supabase con la extensión pgvector. Para empezar, Pinecone tiene un plan gratuito generoso que es perfecto para pruebas.
Paso 1 – Preparar y vectorizar tus documentos
El primer paso es el más importante: preparar tus documentos para que el sistema RAG pueda trabajar con ellos. Este proceso se llama indexación y consta de tres fases.
Formatos soportados (PDF, web, Google Drive)
n8n puede trabajar con múltiples formatos de documentos gracias a sus nodos especializados. Los más comunes son:
PDFs: usando el nodo Extract from File para extraer el texto
Páginas web: con el nodo HTTP Request y HTML Extract para hacer scraping
Google Drive: conexión directa con Google Docs y Google Sheets
Notion: a través de la API de Notion puedes extraer páginas completas
Bases de datos: conectando con MySQL, PostgreSQL o cualquier base de datos
Lo importante es que todo el contenido termine convertido en texto plano antes de pasar a la siguiente fase. n8n facilita esta conversión con nodos específicos para cada formato.
Chunking: dividir documentos en fragmentos
El chunking es el proceso de dividir tus documentos en fragmentos más pequeños. ¿Por qué? Porque los modelos de IA tienen un límite de tokens (contexto) y porque es mucho más eficiente buscar en fragmentos específicos que en documentos completos.
Las estrategias de chunking más efectivas son:
Chunking por tamaño fijo: fragmentos de 500-1000 tokens con solapamiento de 100-200 tokens
Chunking por párrafos: dividir por párrafos naturales del documento
Chunking semántico: usar IA para detectar cambios de tema y dividir inteligentemente
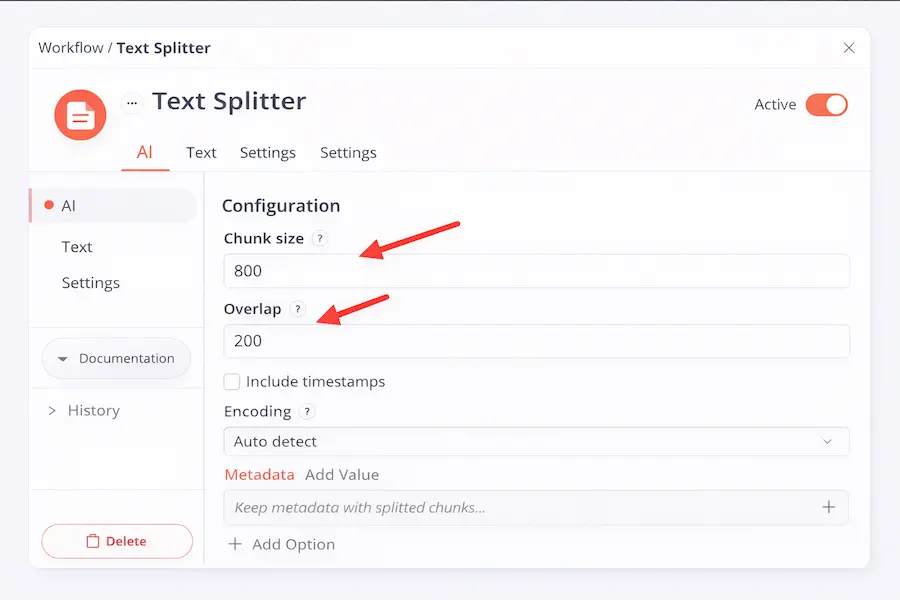
En n8n, el nodo Text Splitter (dentro del módulo AI) permite configurar el tamaño de los fragmentos y el solapamiento (overlap), que es crucial para no perder contexto entre fragmentos. Un buen punto de partida es usar chunks de 800 tokens con un overlap de 200.
Configuración del chunking en n8n con el nodo Text Splitter
Generar embeddings y almacenarlos
Una vez que tienes tus fragmentos de texto, necesitas convertirlos en vectores numéricos (embeddings). Estos vectores son representaciones matemáticas que capturan el significado semántico del texto. Así, cuando un usuario pregunte algo, el sistema puede encontrar los fragmentos más relevantes semánticamente, no solo los que contienen las mismas palabras.
En n8n, puedes usar el nodo Embeddings OpenAI (con el modelo text-embedding-3-small, que es barato y eficaz) o el nodo Embeddings Google para generar los vectores. Después, el nodo Vector Store Insert los almacena en tu base de datos vectorial elegida (Pinecone, Qdrant o Supabase).
El flujo completo de indexación en n8n sería: Trigger manual → Leer documentos → Extraer texto → Text Splitter → Embeddings → Vector Store Insert. Una vez ejecutado, tus documentos estarán listos para ser consultados.
Paso 2 – Construir el flujo RAG en n8n
Ahora viene la parte más emocionante: construir el flujo RAG que procesará las preguntas de los usuarios y generará respuestas inteligentes basadas en tus propios datos.
Recibir la pregunta del usuario
El primer nodo de tu flujo debe ser un trigger que reciba la pregunta. Dependiendo del canal, usarás:
Webhook: para recibir preguntas desde tu web o cualquier aplicación externa
n8n Chat Trigger: el widget de chat integrado de n8n, perfecto para pruebas
Telegram/WhatsApp Trigger: para chatbots en mensajería instantánea
Lo importante es que la pregunta del usuario llegue como una cadena de texto que puedas pasar a los siguientes nodos. Si vienes de nuestro curso de n8n, ya sabrás cómo configurar estos triggers.
Buscar documentos relevantes (retrieval)
Una vez que tienes la pregunta, necesitas buscar los fragmentos más relevantes en tu vector store. En n8n, esto se hace con el nodo Vector Store Retriever, que convierte la pregunta en un embedding y busca los fragmentos más similares.
Los parámetros clave que debes configurar son:
Top K: cuántos fragmentos recuperar (normalmente entre 3 y 5)
Score threshold: umbral mínimo de similitud para incluir un fragmento
Metadata filters: filtros adicionales por categoría, fecha u otros metadatos
Un Top K de 4 suele ser un buen equilibrio entre tener suficiente contexto y no sobrecargar el prompt del modelo de IA.
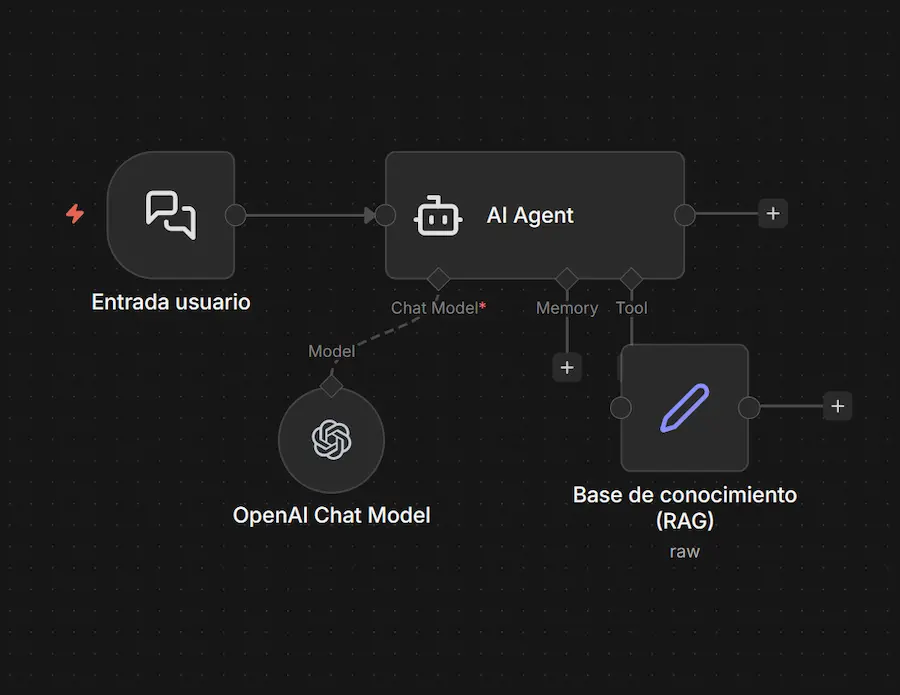
Flujo RAG completo en el editor visual de n8n
Generar respuesta con contexto (generation)
La fase final es la generación. Los fragmentos recuperados se insertan en el prompt del sistema junto con la pregunta del usuario, y el modelo de IA genera una respuesta basada en esa información. En n8n, el nodo AI Agent maneja todo esto de forma integrada.
El prompt del sistema es crucial para obtener buenas respuestas. Un ejemplo efectivo sería: “Eres un asistente de atención al cliente de [empresa]. Responde únicamente basándote en el contexto proporcionado. Si no encuentras la información, di que no la tienes y sugiere contactar con soporte. Sé amable y conciso.”
Este prompt garantiza que el chatbot no invente respuestas y mantiene un tono profesional. Puedes personalizarlo según las necesidades de tu negocio.
Paso 3 – Conectar con WhatsApp, web o email
Un chatbot RAG no sirve de nada si los usuarios no pueden acceder a él. Aquí tienes las opciones más populares para desplegar tu chatbot:
Widget web con n8n Chat: n8n incluye un widget de chat que puedes incrustar en cualquier página web con un simple código JavaScript. Es la opción más rápida para empezar y no requiere ninguna herramienta adicional.
WhatsApp Business API: conectando con la API de WhatsApp Business a través de proveedores como 360dialog o Twilio, puedes tener tu chatbot respondiendo por WhatsApp. Es ideal para atención al cliente porque tus clientes ya están en WhatsApp.
Telegram: una opción gratuita y muy fácil de configurar. El nodo de Telegram en n8n permite crear un bot en minutos.
Email: puedes configurar un flujo que monitorice una bandeja de entrada, procese las preguntas con RAG y envíe respuestas automáticas. Perfecto para soporte técnico que funciona 24/7.
Si quieres explorar más integraciones, en el curso de Agentes IA enseñamos cómo conectar chatbots con múltiples canales simultáneamente.
Paso 4 – Mejorar la precisión del chatbot
Tu primer chatbot RAG funcionará, pero seguramente necesitará ajustes para dar respuestas realmente buenas. Aquí tienes las tres áreas clave para mejorar la precisión.
Ajustar el chunking
El tamaño de los chunks tiene un impacto enorme en la calidad de las respuestas. Chunks demasiado pequeños pueden perder contexto importante. Chunks demasiado grandes pueden incluir información irrelevante que confunda al modelo. Experimenta con diferentes tamaños: 500, 800, 1200 tokens, y evalúa cuál da mejores resultados con tus documentos específicos.
También es importante el overlap (solapamiento). Un overlap de 20-25% del tamaño del chunk suele funcionar bien para mantener la coherencia entre fragmentos contiguos.
Mejorar los prompts del sistema
El prompt engineering es un arte que marca la diferencia entre un chatbot mediocre y uno excelente. Algunas técnicas que funcionan muy bien:
Definir un rol claro para el chatbot (experto en producto, soporte técnico, asesor comercial)
Incluir instrucciones específicas sobre el tono y la extensión de las respuestas
Añadir ejemplos de respuestas ideales (few-shot prompting)
Indicar explícitamente que no invente información si no la encuentra en el contexto
Añadir fallback a humano
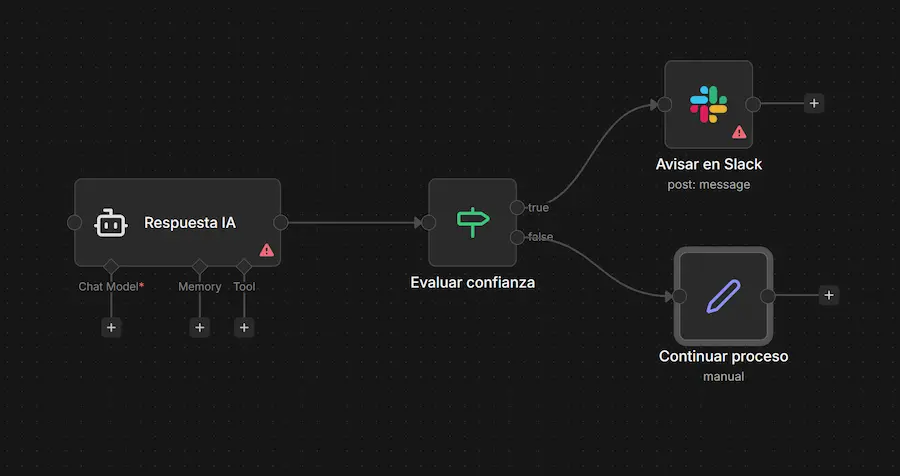
Ningún chatbot puede responder todas las preguntas. Es fundamental implementar un sistema de escalado a humano cuando el bot no puede ayudar. En n8n, puedes detectar cuándo la confianza es baja (por ejemplo, cuando el score de similitud es inferior a un umbral) y enviar automáticamente una notificación a tu equipo por Slack, email o cualquier otro canal.
Esta combinación de automatización + intervención humana es la clave para ofrecer una experiencia de soporte excepcional.
Implementación de fallback a humano en el flujo RAG de n8n
Ejemplo real: chatbot RAG para documentación interna
Vamos a ver un caso práctico que implementamos en VA360 Academy: un chatbot que responde preguntas sobre documentación interna de procesos. Este ejemplo te servirá como referencia para tu propio proyecto.
El problema: el equipo pasaba horas semanales buscando información en documentos de Google Drive y respondiendo las mismas preguntas una y otra vez. La documentación existía, pero encontrar la respuesta correcta llevaba demasiado tiempo.
La solución: un chatbot RAG construido con n8n que indexó más de 200 documentos de Google Drive, manuales PDF y páginas de Notion. El chatbot se conectó a Slack y a un widget web para que cualquier miembro del equipo pudiera hacer preguntas.
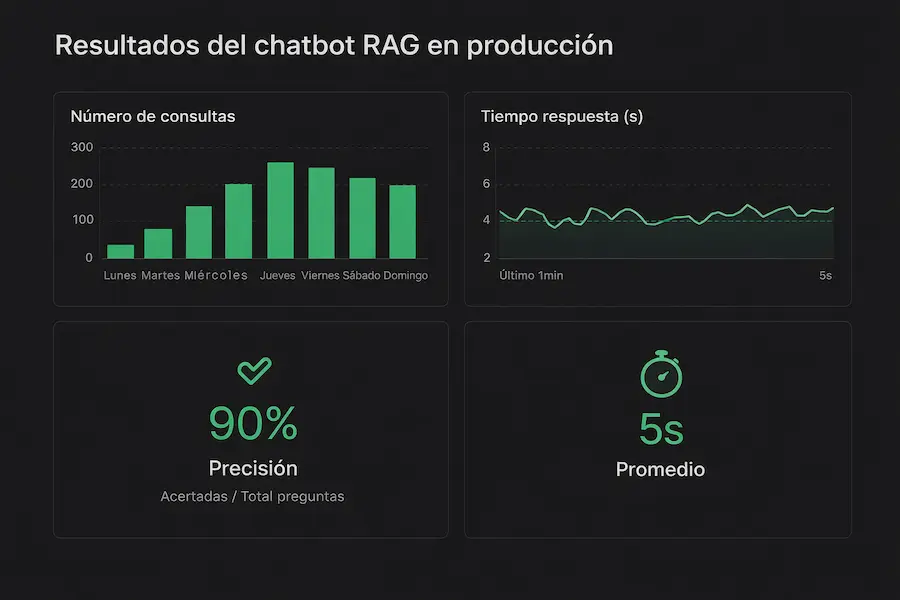
Los resultados:
Reducción del 70% del tiempo dedicado a buscar información
Precisión del 90% en las respuestas del chatbot
Respuesta inmediata frente a los minutos u horas anteriores
Coste mensual inferior a 30€ (API de OpenAI + Pinecone gratuito)
La configuración técnica fue: n8n Cloud + OpenAI text-embedding-3-small para embeddings + GPT-4o mini para generación + Pinecone como vector store. El flujo de indexación se ejecuta automáticamente cada noche para detectar documentos nuevos o actualizados.
Este es exactamente el tipo de proyecto que enseñamos paso a paso en nuestros cursos. Si quieres replicar algo así en tu empresa, el curso de Agentes IA es el lugar perfecto para empezar.
Y si quieres acceder a todos los cursos de automatización, agentes IA, n8n y más, el Máster en Automatizaciones y Agentes IA te da acceso de por vida a todo el contenido por solo 297€. Es la inversión más rentable que puedes hacer si quieres dominar estas tecnologías.
Resultados del chatbot RAG en producción
Aprende RAG y agentes IA en VA360 Academy
Si has llegado hasta aquí, ya tienes una visión completa de cómo funciona un chatbot RAG con n8n. Pero implementarlo correctamente requiere práctica y conocimiento profundo de las herramientas. En VA360 Academy te enseñamos todo lo que necesitas para pasar de la teoría a la práctica.
Nuestros cursos están diseñados por Valentín Ayesa, embajador oficial de n8n en España, y ya han formado a más de 2.000 alumnos. No importa si eres principiante o si ya tienes experiencia con automatizaciones; tenemos el contenido adecuado para ti.
Estas son las formaciones más relevantes para RAG y agentes IA:
Curso de n8n 2026: domina n8n desde cero, incluyendo los nodos de IA
Curso de Agentes IA: aprende a crear agentes inteligentes con RAG, tools y memory
Masterclass gratuita: empieza gratis y descubre el potencial de la automatización
Además, puedes unirte a nuestra comunidad gratuita donde compartimos recursos, resolvemos dudas y publicamos actualizaciones sobre las últimas novedades de n8n, IA y automatización.
Preguntas frecuentes
Qué precisión tiene un chatbot RAG?
La precisión de un chatbot RAG depende directamente de la calidad de tus documentos, la estrategia de chunking y los prompts del sistema. En nuestra experiencia, un sistema RAG bien configurado alcanza una precisión del 85-95% en las respuestas. La clave está en iterar: analizar las respuestas incorrectas, ajustar el chunking, mejorar los prompts y enriquecer la base de conocimiento. Con n8n, este proceso de mejora continua es muy sencillo porque puedes modificar el flujo y probar cambios en minutos.
Puedo usarlo con documentos privados de forma segura?
Sí, la seguridad es uno de los puntos fuertes de implementar RAG con n8n. Si usas n8n autoalojado, tus documentos nunca salen de tu servidor excepto cuando se envían a la API del modelo de IA para generar embeddings o respuestas. Puedes usar Qdrant autoalojado como vector store para mantener todo en tu infraestructura. Si la privacidad es crítica, también puedes usar modelos locales con Ollama para que absolutamente nada salga de tu servidor. Ten en cuenta que OpenAI y Anthropic no usan los datos de sus APIs para entrenar modelos, lo que ofrece un nivel de privacidad aceptable para la mayoría de casos empresariales.
Cuánto cuesta mantener un chatbot RAG?
El coste mensual de un chatbot RAG depende del volumen de consultas y del modelo que uses. Para darte una referencia: con 1.000 consultas mensuales usando GPT-4o mini y Pinecone gratuito, el coste ronda los 5-15€ al mes solo en API. Si usas n8n Cloud, añade el coste de la suscripción (desde 20€/mes). Si autoalojas n8n, el coste es el del servidor (desde 5€/mes en un VPS). En total, puedes tener un chatbot RAG profesional por 25-50€ al mes, lo cual es increíblemente barato comparado con los miles de euros que cuestan las soluciones SaaS específicas.
RAG vs fine-tuning: cuál es mejor?
RAG y fine-tuning son técnicas complementarias, pero para la mayoría de casos de uso empresarial, RAG es claramente superior. El fine-tuning requiere entrenar (o ajustar) un modelo con tus datos, lo cual es caro, lento y difícil de actualizar. RAG, en cambio, permite actualizar la información en tiempo real simplemente añadiendo nuevos documentos al vector store. Además, RAG proporciona trazabilidad: puedes ver exactamente qué fragmentos usó el modelo para generar la respuesta, algo imposible con fine-tuning. La única ventaja del fine-tuning es cuando necesitas cambiar el estilo o comportamiento del modelo de forma muy específica, pero incluso en ese caso, un buen prompt engineering suele ser suficiente.
Crear un chatbot RAG con n8n es una de las mejores formas de llevar la inteligencia artificial a tu negocio de forma práctica y con resultados inmediatos. Ya no hay excusas para seguir respondiendo las mismas preguntas una y otra vez o para tener documentación que nadie puede encontrar. Con las herramientas y técnicas que hemos visto en esta guía, tienes todo lo necesario para empezar hoy mismo. Y si quieres ir más rápido y con acompañamiento experto, nos vemos en VA360 Academy. Tu primer chatbot inteligente está a unas pocas horas de distancia.
Para ofrecer las mejores experiencias, utilizamos tecnologías como las cookies para almacenar y/o acceder a la información del dispositivo. El consentimiento de estas tecnologías nos permitirá procesar datos como el comportamiento de navegación o las identificaciones únicas en este sitio. No consentir o retirar el consentimiento, puede afectar negativamente a ciertas características y funciones.
Funcional
Siempre activo
El almacenamiento o acceso técnico es estrictamente necesario para el propósito legítimo de permitir el uso de un servicio específico explícitamente solicitado por el abonado o usuario, o con el único propósito de llevar a cabo la transmisión de una comunicación a través de una red de comunicaciones electrónicas.
Preferencias
El almacenamiento o acceso técnico es necesario para la finalidad legítima de almacenar preferencias no solicitadas por el abonado o usuario.
Estadísticas
El almacenamiento o acceso técnico que es utilizado exclusivamente con fines estadísticos.El almacenamiento o acceso técnico que se utiliza exclusivamente con fines estadísticos anónimos. Sin un requerimiento, el cumplimiento voluntario por parte de tu proveedor de servicios de Internet, o los registros adicionales de un tercero, la información almacenada o recuperada sólo para este propósito no se puede utilizar para identificarte.
Marketing
El almacenamiento o acceso técnico es necesario para crear perfiles de usuario para enviar publicidad, o para rastrear al usuario en una web o en varias web con fines de marketing similares.