Web scraping con IA, n8n y Firecrawl: crea tu newsletter automática

El web scraping ha evolucionado enormemente gracias a la inteligencia artificial. Ya no hace falta lidiar con selectores CSS, estructuras HTML complicadas o protecciones anti-bot que bloquean tus scripts. En este artículo te enseño cómo combinar Firecrawl, n8n y modelos de IA para crear un sistema de scraping automático que extrae noticias de múltiples fuentes, las resume con inteligencia artificial y las almacena en una base de datos lista para generar una newsletter automática. Todo el proceso, de principio a fin, paso a paso.
Índice
Qué es Firecrawl y por qué es mejor que el scraping tradicional
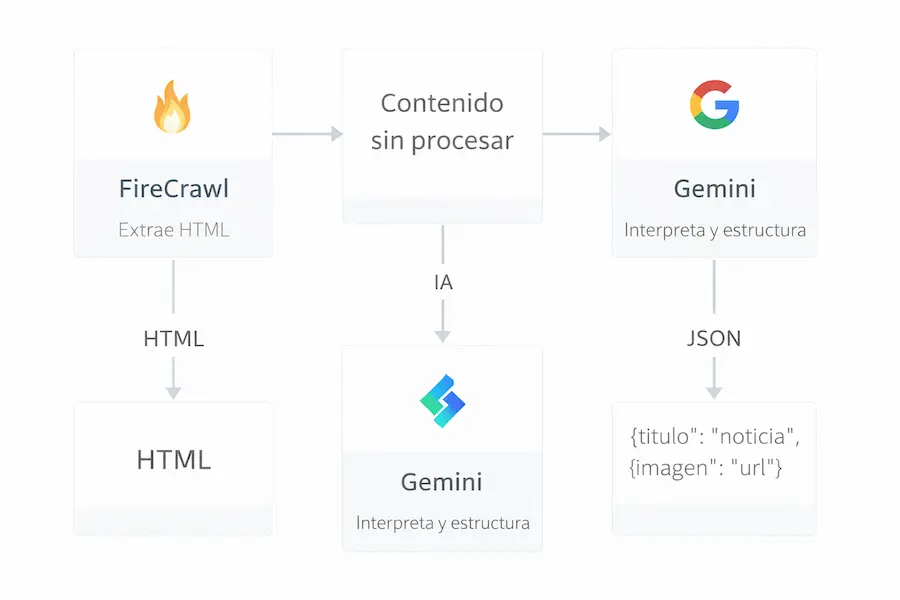
Firecrawl es una herramienta de web scraping con inteligencia artificial que permite extraer contenido de cualquier página web sin importar cómo esté construida. A diferencia del scraping tradicional donde necesitas analizar la estructura del HTML, identificar selectores CSS y lidiar con JavaScript dinámico, Firecrawl simplemente recibe una URL y te devuelve el contenido en formato limpio: Markdown, HTML o JSON.
¿Por qué es mejor que las herramientas de scraping tradicionales? Por varias razones fundamentales. Primero, no te importan las protecciones anti-bot: Firecrawl las gestiona automáticamente. Segundo, no necesitas escribir código personalizado para cada web que quieras escrapear. Tercero, puede devolverte el contenido en el formato que más te convenga para su procesamiento posterior. Y cuarto, tiene una integración directa con n8n a través de nodos disponibles en la comunidad, lo que simplifica enormemente la automatización.
En el scraping tradicional, cambiar una sola clase CSS en la web objetivo puede romper todo tu sistema. Con Firecrawl y la IA, eso deja de ser un problema. La herramienta interpreta el contenido de forma inteligente y te lo entrega estructurado y limpio, listo para ser procesado. Si quieres entender cómo n8n potencia este tipo de integraciones, puedes leer nuestro artículo sobre qué es n8n y sus ventajas principales.
Cómo funciona el scraping con IA
El flujo completo de scraping con inteligencia artificial tiene tres fases diferenciadas que trabajan en cadena. Cada fase cumple un papel específico y juntas crean un sistema potente y automatizado que puede funcionar sin intervención humana. Vamos a desglosar cada una.
Firecrawl extrae el contenido
La primera fase es la extracción de contenido. Firecrawl recibe las URLs de las páginas web que quieres escrapear y se encarga de navegar, renderizar JavaScript si es necesario, superar protecciones y extraer todo el contenido relevante. Puedes usar dos modos principales: Scrape para una sola página y Crawl para recorrer múltiples páginas de un mismo sitio.
En el modo Crawl, Firecrawl navega por las diferentes páginas del sitio web, extrayendo el contenido de cada una y devolviéndote todo en un paquete organizado. Puedes configurar un límite de páginas para no exceder tus créditos y también puedes incluir opciones como extraer los links de las páginas y el contenido HTML. Esta flexibilidad es clave para adaptar el scraping a tus necesidades específicas.
Un detalle técnico importante: cuando usas el modo Crawl a través de la API de Firecrawl, la extracción no es instantánea. Envías el trabajo y la API te avisa cuando ha terminado, ya sea a través de un webhook de callback o comprobando el estado del trabajo periódicamente. En n8n, puedes gestionar esto con un nodo Wait que espera la notificación del webhook, o con un bucle que comprueba el estado hasta que el crawl se complete.
La IA lo interpreta y resume
Una vez que tienes el contenido HTML extraído, la segunda fase es usar un modelo de inteligencia artificial para interpretarlo y extraer la información relevante. En el tutorial se usa un nodo AI Agent con el modelo Gemini como procesador de lenguaje natural, al que se le pasa el HTML y se le pide que devuelva un JSON estructurado con las noticias encontradas.
El system prompt del agente es clave: se le indica que es un agente que recibe un HTML de una web escrapeada y debe devolver un JSON válido y puro con todas las noticias y la información relevante de cada una. Los campos que se le piden incluyen título, autor, fecha, resumen, imagen y fuente. La IA interpreta el HTML desestructurado y lo convierte en datos limpios y organizados.
¿Por qué Gemini y no otro modelo? En este caso se eligió porque es prácticamente gratuito y ofrece resultados muy buenos para este tipo de tareas de extracción y estructuración de datos. Pero podrías usar cualquier modelo compatible con n8n: OpenAI, Claude, Mistral o cualquier otro que prefieras. Lo importante es que el prompt esté bien definido para obtener resultados consistentes.
n8n lo automatiza y envía
La tercera fase es donde n8n brilla como orquestador de automatizaciones. Una vez que la IA ha procesado el contenido y te devuelve un JSON estructurado con las noticias, n8n se encarga de almacenar la información en una base de datos, gestionar el bucle de múltiples fuentes web y programar la ejecución para que todo funcione de forma desatendida.
La ventaja de usar n8n frente a otras herramientas como Make o Zapier es que al tenerlo instalado en tu propio servidor, puedes hacer tantas pruebas como quieras sin que cada ejecución te cueste dinero adicional. Cuando estás desarrollando un flujo de scraping que requiere muchas iteraciones y ajustes, esta libertad para experimentar marca la diferencia. Puedes equivocarte las veces que necesites y perfeccionar el sistema hasta que funcione exactamente como quieres. Si te interesa dominar n8n a fondo, el curso de n8n de cero a experto es el recurso más completo.
Vamos con el tutorial práctico. El objetivo es crear un sistema que cada día escrapee 10 páginas web de noticias sobre inteligencia artificial, extraiga las noticias con IA, las almacene en una base de datos MySQL y las muestre en una página web que funcione como newsletter interactiva. Paso a paso, sin saltarnos nada.
Configurar Firecrawl
Lo primero es registrarte en Firecrawl y obtener tu API Key. El proceso es rápido: creas una cuenta, accedes al dashboard y desde ahí puedes ver tus estadísticas de uso y obtener tu clave. El plan gratuito te permite hacer un número limitado de scrapes, pero es más que suficiente para empezar y probar.
Antes de integrarlo con n8n, puedes probar Firecrawl desde su playground. Pega una URL, configura las opciones (como incluir page links o el HTML) y ejecuta un scrape de prueba para ver qué te devuelve. Esto te ayuda a entender el formato de los datos y a decidir qué tipo de extracción necesitas para tu caso.
Un detalle importante sobre la instalación del nodo de Firecrawl en n8n: no viene instalado por defecto. Tienes que ir a Settings → Community Nodes y buscar “n8n-nodes-firecrawl”. Hay varias opciones disponibles; se recomienda instalar el que tiene más descargas ya que suele estar más probado y mantenido. Una vez instalado, tendrás disponibles nodos para enviar trabajos de crawl, comprobar el estado y extraer información.
Crear el flujo en n8n
El flujo en n8n empieza con un trigger manual (o uno temporal para ejecución programada) seguido de un nodo Set donde defines las URLs de las fuentes que quieres escrapear. En el tutorial se usó Perplexity para obtener las 10 mejores páginas web con noticias de inteligencia artificial, y se las pidió en formato JSON para poder importarlas directamente en n8n.
A continuación, necesitas un nodo Split Out para separar las URLs en ítems individuales, y después un nodo Loop Over Items para procesar cada URL una a una. ¿Por qué un loop? Porque cada scrape implica una llamada a la API externa de Firecrawl que puede tardar varios segundos o minutos, y procesar todo en paralelo podría sobrecargar el sistema.
Dentro del loop, conectas el nodo de Firecrawl configurado con tu API Key. Le pasas la URL del ítem actual y configuras un límite de páginas (por ejemplo, 5 para no alargar demasiado el proceso). La URL viene del Loop Over Items, así que cada iteración procesará una fuente diferente. Si necesitas que n8n espere a que Firecrawl termine, puedes usar un nodo Wait con webhook callback o un bucle de comprobación de estado.
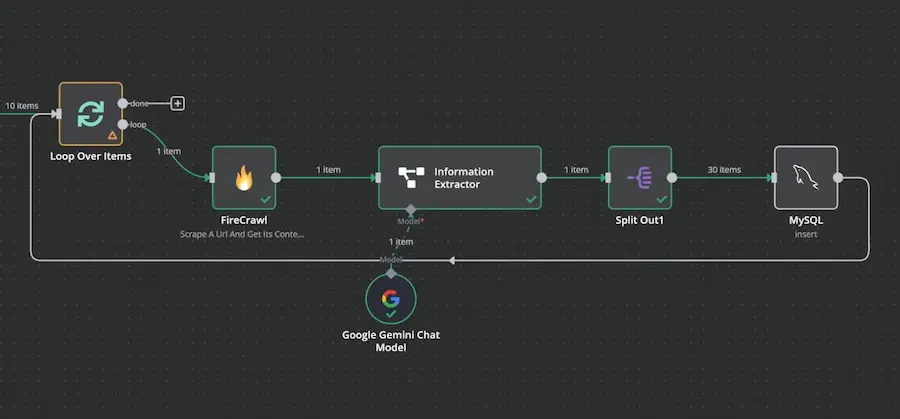
Añadir IA para resumir contenido
Una vez que Firecrawl devuelve el HTML extraído, conectas un nodo AI Agent (o un nodo de procesamiento de IA básico) que recibe ese HTML y lo transforma en datos estructurados. La configuración del agente incluye:
- System prompt: “Eres un agente de IA que recibe un HTML de una web escrapeada y devuelve un JSON válido y puro con todas las noticias y la información relevante de cada una.”
- Modelo: Gemini Flash (gratuito y rápido) o cualquier otro modelo compatible.
- Formato de salida: JSON con campos para título, autor, fecha, resumen, imagen y fuente.
El truco para obtener buenos resultados es ser muy específico en el prompt sobre los campos que quieres. En el tutorial se usó ChatGPT para generar la plantilla JSON de N8N que define la estructura de salida esperada: título, autor, fecha, resumen, imagen y fuente. Esto le da al modelo una guía clara sobre cómo formatear la respuesta. También es importante solicitar la imagen de la noticia si está disponible en el HTML, ya que es un dato valioso para la presentación visual posterior.
Después del procesamiento con IA, necesitas un segundo Split Out para separar las noticias individuales del JSON que devuelve el modelo. De esta forma, cada noticia se convierte en un ítem independiente de n8n, listo para ser almacenado en la base de datos. Si quieres aprender más sobre cómo combinar IA con automatizaciones, el curso de agentes de IA te dará una base sólida.
Enviar por email automáticamente
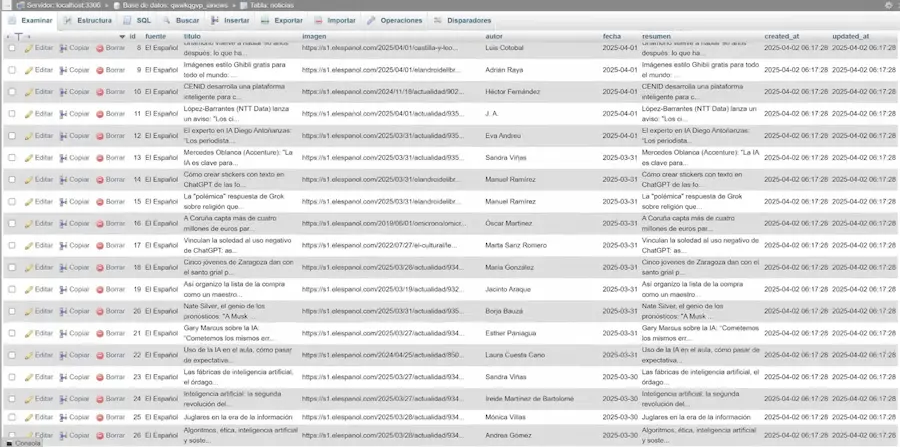
El paso final es almacenar las noticias en una base de datos y hacer que estén disponibles para su distribución. En el tutorial se usó una base de datos MySQL con una tabla de noticias que incluye campos para ID, fuente, título, imagen, autor, fecha y resumen. La tabla se crea fácilmente con un script SQL generado por IA a partir de los campos que necesitas.
Para la conexión con MySQL desde n8n, usas el nodo MySQL configurado con las credenciales de tu servidor. Un punto importante que destaca en el tutorial: n8n es capaz de gestionar lotes de elementos sin necesidad de usar un loop adicional. Si tienes 30 noticias, el nodo MySQL las insertará todas automáticamente. El loop se usa específicamente para las llamadas a la API de Firecrawl porque implican carga de servidor externa, pero para operaciones internas como inserciones en base de datos, n8n las procesa en lote eficientemente.
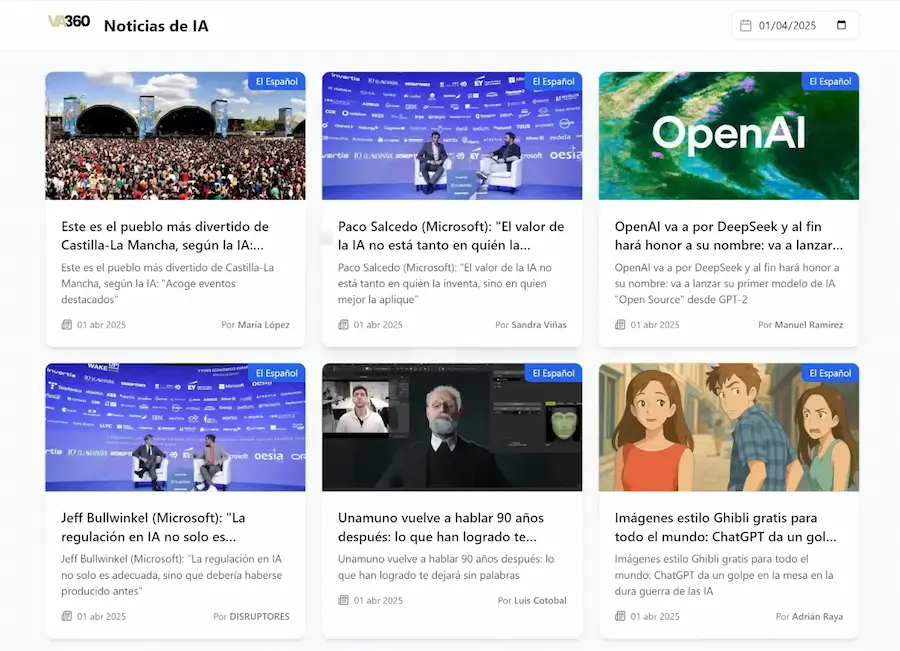
Para convertir esto en una newsletter real, puedes crear un frontend con herramientas de vibe coding como Lovable o Bolt que se conecte a tu base de datos y muestre las noticias filtradas por fecha. En el tutorial se demostró cómo hacerlo con ambas herramientas, obteniendo una página funcional que muestra las noticias del día con sus títulos, imágenes y resúmenes. Si prefieres enviarlas por correo electrónico, simplemente añades un nodo de email al final del flujo que genere un HTML bonito con las noticias del día y lo envíe a tu lista de suscriptores. Si el vibe coding te interesa, echa un vistazo al curso de VibeCoding de cero a experto.
Y para automatizar la ejecución diaria, solo tienes que sustituir el trigger manual por un trigger temporal (Schedule Trigger) que ejecute el flujo a una hora específica cada día. También es recomendable añadir validaciones para evitar duplicados, comprobando si una noticia ya existe en la base de datos antes de insertarla.
Otros usos del scraping con IA y n8n
Aunque la newsletter automática es un caso de uso fantástico, el scraping con IA combinado con n8n abre un mundo de posibilidades. Aquí tienes algunas ideas para que te inspires y pienses en cómo aplicarlo a tu negocio o proyectos personales.
- Monitorización de precios de la competencia: Escrapea las páginas de productos de tus competidores diariamente, extrae los precios con IA y genera alertas cuando haya cambios significativos. Ideal para ecommerce.
- Seguimiento de ofertas de empleo: Configura un scraping de portales de empleo en tu sector, extrae las ofertas relevantes con IA y recibe un resumen diario en tu correo o en Slack.
- Investigación de mercado: Extrae opiniones de usuarios de foros, redes sociales o plataformas de reseñas, y usa la IA para analizar sentimientos, tendencias y patrones.
- Generación de contenido: Escrapea fuentes de información relevantes para tu nicho y usa la IA para generar borradores de artículos, posts para redes sociales o informes resumidos.
- Vigilancia tecnológica: Monitoriza blogs técnicos, repositorios de GitHub o foros especializados para estar al día de las últimas novedades en tu campo.
La clave de todos estos usos es la misma: Firecrawl se encarga de la extracción, la IA interpreta y estructura los datos, y n8n automatiza todo el proceso para que funcione sin tu intervención. Si quieres aprender a construir cualquiera de estos sistemas, tanto el curso de n8n como el Máster en Automatizaciones y Agentes IA te dan las herramientas y el conocimiento necesarios. Y si tienes dudas, en la comunidad VA360 PRO siempre hay profesionales dispuestos a ayudarte.
Aprende scraping y automatización en VA360 Academy
El scraping con inteligencia artificial es solo una de las muchas técnicas que puedes dominar para llevar tus proyectos al siguiente nivel. En VA360 Academy enseñamos desde los fundamentos de la automatización hasta las técnicas más avanzadas de agentes de IA, web scraping, procesamiento de datos y mucho más.
Dentro del curso de n8n de cero a experto encontrarás los escenarios completos para descargar y ejecutar en tu propio n8n, incluyendo flujos de scraping como el que has visto en este artículo. Si quieres ir más allá y aprender a crear agentes de IA que procesen y analicen datos automáticamente, también tenemos un curso específico para ello. Puedes empezar echando un vistazo a nuestra masterclass gratuita de automatizaciones para ver si el contenido se adapta a lo que buscas. Y si buscas herramientas complementarias, te interesará también Make.com como alternativa para ciertos flujos de automatización.
Preguntas frecuentes
¿Es legal hacer web scraping con Firecrawl y n8n?
El web scraping en sí no es ilegal, pero debes respetar los términos de servicio de cada web que escrapees y las leyes de protección de datos aplicables. Firecrawl es una herramienta legítima que respeta los archivos robots.txt de los sitios web. Sin embargo, es tu responsabilidad asegurarte de que el uso que haces de los datos extraídos cumple con la normativa vigente y no infringe derechos de autor ni términos de uso.
¿Firecrawl es gratuito o necesito pagar?
Firecrawl tiene un plan gratuito que incluye un número limitado de créditos mensuales para hacer scrapes. Es suficiente para probar y para proyectos pequeños. Para un uso más intensivo, necesitarás un plan de pago. La buena noticia es que los precios son razonables y, combinado con n8n autoalojado, el coste total de un sistema de scraping profesional es muy bajo comparado con soluciones comerciales.
¿Por qué el scraping tarda tanto en completarse?
El modo Crawl de Firecrawl navega por múltiples páginas de un sitio web, renderiza JavaScript, supera protecciones y extrae contenido de cada una. Esto lleva tiempo, especialmente si configuras un límite alto de páginas. Por eso es importante usar un nodo Wait o un sistema de comprobación de estado en n8n. Para reducir tiempos, baja el límite de páginas o usa el modo Scrape para URLs específicas en lugar de Crawl para sitios completos.
¿Puedo usar otro modelo de IA en lugar de Gemini?
Absolutamente. n8n es compatible con múltiples modelos de IA: OpenAI (GPT-4), Claude de Anthropic, Mistral, Llama y muchos más. En el tutorial se usó Gemini porque es prácticamente gratuito y los resultados son excelentes para tareas de extracción y estructuración de datos. Pero puedes sustituirlo por el modelo que prefieras sin modificar nada más del flujo.
¿Cómo evito noticias duplicadas en la base de datos?
Hay varias estrategias. La más simple es añadir un nodo de comprobación antes de la inserción que busque si ya existe una noticia con el mismo título o URL. También puedes configurar un índice único en la base de datos para el campo de título, de forma que MySQL rechace automáticamente los duplicados. Otra opción es usar el nodo MySQL con la operación “Insert or Update” que actualiza el registro si ya existe en lugar de crear uno nuevo.